
AI Content Best Practices for 2026: Quality at Scale

AI Content Best Practices for 2026: Quality at Scale
According to HumanizeAI's analysis of recent industry data, 71% of marketers say AI lets them produce significantly more content, yet 52% believe it's actually reducing overall content effectiveness. That gap tells you everything about where most teams went wrong.
They optimized for speed. Not strategy.
Google's Helpful Content system, AI Overviews, and LLM-driven search engines have rewritten what "quality" means since 2024, and only 14% of top-ranking search results are AI-generated, despite AI tools flooding the web with millions of new pages monthly. The old "prompt, publish, pray" workflow doesn't build topical authority or earn visibility in a SERP shaped by AI Overviews.
The teams still treating AI as a production shortcut are the ones watching their organic traffic flatline. High-performers shifted to a "Prompt, Collaborate, Improve, Publish" model, embedding human expertise at every stage rather than bolting it on at the end.
This piece breaks down the operational best practices that separate high-performing AI content teams from everyone else in 2026: prompt engineering, E-E-A-T integration, GEO, and AEO optimization strategies that most competitor guides only skim.
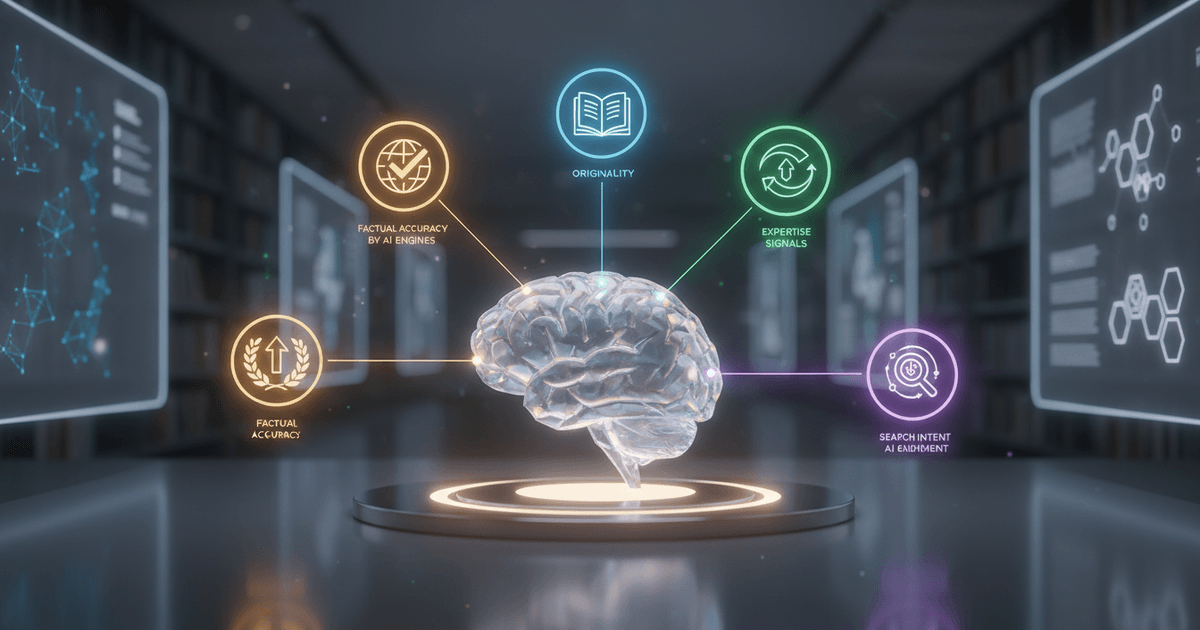
What Does High-Quality AI Content Actually Look Like in 2026?
Quality AI content in 2026 comes down to five pillars: factual accuracy, originality, expertise signals, search intent alignment, and citability by AI engines.
Google doesn't penalize AI content. It penalizes thin, unhelpful content, regardless of who or what produced it. That distinction matters more than most people realize. 80% of content teams now have formal accuracy guidelines for AI output. Yet most still treat quality like a simple pass/fail checkbox. It's not. Quality exists on a spectrum, and where you fall on it depends entirely on content type.
Here's how the five pillars break down:
- Accuracy goes well beyond fact-checking. It means citing verifiable sources, cross-referencing claims, and being honest about where data is uncertain rather than confidently getting it wrong.
- Originality is the hardest quality to scale. Human-assisted content still dominates rankings at a disproportionate rate. That's a clear signal: search engines can tell the difference between rehashed summaries and genuine analysis.
- Expertise signals require first-hand knowledge. You demonstrate this through specific examples, practitioner language, and a depth of insight no generic prompt can replicate.
- Search intent alignment means matching your format and depth to what the searcher actually needs, not just what's easiest to generate.
- Citability is the newest pillar. According to Typeface's research, 88% of AI Overviews target informational queries. Your content needs to be structured so AI engines can extract and reference it cleanly. If it isn't, you're invisible in that channel.
That last point deserves more attention than the others. Citability is where most teams fall behind. They're still optimizing for traditional SERPs and completely ignoring how LLMs pick their sources.
Not all content carries the same risk. YMYL topics, think health, finance, and legal, demand expert authorship and cited sources well beyond what a typical blog post requires. Informational content needs semantic depth and conversational readiness. Transactional pages? They depend on trust signals and precise product details. Treating all three identically is how teams burn through their quality review budget with absolutely nothing to show for it.
The AI content trends reshaping publishing in 2026 point to one clear pattern. Content that earns visibility is built with purposeful strategy, not just pumped out at scale. The quality bar isn't about perfection. It's about showcasing topical expertise through substance that real people and AI engines alike recognize as genuinely useful.
How Does Prompt Engineering Improve AI Content Output?
Prompt engineering reduces AI hallucinations and revision cycles by structuring inputs around role assignment, context injection, and constraint setting for each content piece.
Most content teams treat prompting like a Google search: type a question, hope for a good answer. That approach produced passable drafts in 2023. In 2026, it produces content that ranks nowhere and says nothing original. According to Digital Third Coast's research, AI-optimized content achieves 32% higher engagement and 47% better conversions, but those numbers only apply when teams use structured prompt frameworks rather than ad-hoc instructions.
The framework that actually works follows five stages: role assignment, context injection, constraint setting, output formatting, and iterative refinement. Think of it less as "writing a prompt" and more as briefing a junior writer who's brilliant but has zero institutional knowledge. You wouldn't hand a new hire a topic and say "write something good." You'd give them your style guide, target audience profile, competitive examples, and specific claims to avoid.
Three prompt patterns consistently outperform generic instructions:
- The Expert Briefing pattern assigns the AI a specific domain role ("You're a B2B fintech analyst with 10 years of experience") and injects proprietary context like internal data or customer pain points.
- The Source-Grounded pattern feeds verified sources directly into the prompt, forcing the model to synthesize rather than generate from its training data. This alone cuts hallucination rates dramatically.
- The Audience Mirror pattern constrains output by defining the reader's expertise level, search intent, and objections they're likely holding.
HubSpot's content team reportedly reduced AI revision cycles by 40% after implementing structured prompt templates across their editorial workflow. Fewer revision cycles means editors spend time adding expertise signals and original analysis instead of fixing factual errors.
The biggest misconception about prompt engineering is that it's about crafting one perfect prompt. The real skill is iterative refinement: reviewing output, tightening constraints, and re-running until the draft matches editorial standards. Teams that build prompt libraries, categorized by content type, funnel stage, and audience segment, consistently produce more effective AI content than those relying on individual creativity each time.
Common advice says "be specific in your prompts." That's true but incomplete. Specificity without constraints produces verbose, over-detailed content. The constraint layer, telling the AI what NOT to do, what claims to avoid, what tone to skip, is where 80% of quality improvement happens. Set word limits per section, and ban certain phrases. Require source citations for every statistical claim. These guardrails transform a mediocre draft into something an editor can actually work with.
Why E-E-A-T Signals Matter More for AI-Assisted Content
Just 14% of top-ranking results are fully AI-generated. The reason? Most AI content doesn't demonstrate the experience and expertise signals that Google's E-E-A-T framework actively rewards.
That figure should stop you from treating AI as a publish button. The gap between AI-generated and human-assisted content on SERPs hinges on one thing: genuine expertise embedded in the content itself, not sprinkled on after the fact.
Here's the contrarian take most teams miss: adding a human editor to AI content doesn't actually solve the expertise problem. Editing on its own can't inject knowledge that was never part of the prompt or workflow in the first place. A copy editor catches grammar mistakes and clunky phrasing. They won't magically supply the clinical trial experience a healthcare article requires, or the deployment war stories a DevOps guide calls for. You need to front-load E-E-A-T at the research and briefing stage. That means feeding subject-matter context, proprietary data, and practitioner insights into the process before a single word gets generated.
According to DesignRush's content marketing research, 65% of content teams now prioritize accuracy and fact-checking in their AI guidelines. That's a decent starting point. But accuracy only covers the "T" in E-E-A-T. Experience and expertise? Those demand a completely different strategy.
A practical E-E-A-T checklist for AI-assisted workflows:
- Author bylines with real credentials tied to the topic (not a vague "content team" attribution)
- First-person experience markers gathered from interviews with internal practitioners or clients
- Cited primary sources with context explaining why the source matters, not just a dropped link
- Original data or proprietary insights your competitors simply can't replicate from a prompt
- Transparent methodology that walks readers through how you actually reached your conclusions
Baking expertise into the briefing stage is what produces content that actually ranks. Tacking it on during review? You end up with AI-generated filler dressed up in footnotes.
This is where many teams run into common AI content challenges: they design workflows built for speed, then can't figure out why their output trips every AI detection flag out there. Content that actually reflects practitioner knowledge doesn't need to trick detection tools. Real expertise shows up in specific ways. Think case references, nuanced trade-off discussions, and opinions rooted in actual outcomes. Those signals naturally separate human-guided AI content from pure machine output.
E-E-A-T isn't something you bolt on after the fact. It's an input. Bake it into your content briefs, your prompt frameworks, and your SME interview process before a single word gets generated.
How to Optimize AI Content for GEO and AEO in 2026
GEO optimizes content for LLM citations in tools like AI Overviews, while AEO targets featured snippets, and both require structural discipline beyond traditional SEO.

Google AI Overviews now appear on 88% of informational queries. That single stat explains why 61% of marketers have increased their SEO budgets specifically to adapt to AI-driven search. Organic search still drives roughly 47% of all website traffic, but the click you used to earn from a blue link now competes with a zero-click answer generated by an LLM. If your content isn't structured for extraction, it's invisible in these new surfaces.
GEO and AEO sound similar. They aren't. GEO is about making your content citable by large language models: Google's AI Overviews, ChatGPT's browsing mode, Perplexity. These systems extract factual claims, definitions, and attributed data points. They favor concise paragraphs between 50 and 150 words, comparison structures, and sentences that begin with clear definition patterns ("X is a..."). AEO targets the featured snippet box and direct answer panels in traditional search. It rewards question-format headings, direct 40 to 60 word opening answers, and FAQ schema markup.
Schema markup has minimal impact on GEO, despite what most guides tell you. LLMs don't parse JSON-LD the way Google's featured snippet algorithm does. What LLMs care about is whether your paragraph reads like a self-contained, factually specific answer that can be quoted without additional context. That's a fundamentally different optimization target.
Here's how the tactics map across all three optimization layers:
| Optimization Tactic | GEO (LLM Citations) | AEO (Featured Snippets) | Traditional SEO |
|---|---|---|---|
| Question-format headings | Moderate impact: helps LLMs identify topic scope | High impact: directly triggers snippet selection | Moderate impact: improves crawl clarity |
| Definition patterns ("X is...") | Critical: LLMs extract these as canonical definitions | High impact: often pulled verbatim into answer boxes | Low direct impact: useful for topical relevance |
| Concise paragraphs (50-150 words) | Critical: optimal extraction length for citations | High impact: snippets favor 40-60 word direct answers | Moderate impact: improves readability signals |
| Numbered/bulleted lists | Moderate impact: LLMs can extract but prefer prose | Critical: list snippets dominate "how to" queries | Moderate impact: improves dwell time |
| Attribution phrases ("According to...") | Critical: signals factual grounding to LLMs | Low impact: snippets rarely include attributions | Low direct impact: supports E-E-A-T perception |
| Schema markup (FAQ, HowTo) | Minimal impact: LLMs don't parse structured data | Critical: enables rich results and snippet eligibility | High impact: drives rich result visibility |
| Internal linking depth | Low direct impact: LLMs evaluate page-level content | Low direct impact: snippet selection is paragraph-level | Critical: distributes domain authority across pages |
GEO vs. AEO vs. Traditional SEO: Which tactics overlap and where they diverge
GEO rewards factual density and attribution. AEO rewards structural formatting. Traditional SEO rewards the connective tissue of internal linking and domain authority. A content piece optimized for only one of these three will underperform against competitors who address all three simultaneously. The 50 to 150 word paragraph sweet spot for GEO also happens to be the ideal length for scannable web content, so optimizing for LLM extraction improves human readability as a side effect.
Teams publishing at scale in 2026 need to bake these structural patterns into their content templates and prompt workflows from the start, not retrofit them during editing.
What Quality Control Framework Should AI Content Teams Follow?
A 4-gate quality control system covering brief validation, accuracy checks, expert review, and post-publish monitoring stops the 36.4% traffic drop that teams without structured evaluations consistently experience.
Most teams treat quality control as one editing pass before they hit publish. That's like quality-testing a car by looking at the paint job. The teams reporting 62.8% traffic growth from AI content? They run a system, not a spot check. And that difference shows up in every metric that matters.
The framework splits into four gates, and each one catches problems the others miss.
Gate 1: Pre-generation brief validation. Before any AI tool generates a single word, the brief itself needs scrutiny. Does it specify search intent? Does it include E-E-A-T requirements like named sources, practitioner quotes, or original data? A brief that says "write about project management" gets you generic filler. But one that says "cover resource allocation failures in construction firms with 50-200 employees, citing PMI data" produces something actually worth reading. Your brief sets the quality ceiling. No amount of editing fixes a weak prompt.
Gate 2: Automated accuracy scan. Cross-reference every claim, statistic, and proper noun against primary sources. Watch for hedging language like "some experts suggest" or "studies show" with zero citation attached. That kind of phrasing almost always masks a hallucination. Here's the thing most people miss: the bigger red flag isn't outright fabrication. It's the plausible-sounding claim that's 80% correct but gets the one detail wrong that actually matters.
Gate 3: Human expert review. This isn't copyediting. A subject matter expert confirms statistics actually match their primary sources, checks that recommendations reflect current practice, and ensures the content shows real expertise. About 65% of high-performing content teams prioritize accuracy checks at this stage. And 59% enforce ethical standards, including AI disclosure policies.
Gate 4: Post-publish performance monitoring. Keep an eye on engagement, dwell time, and ranking shifts over 30 to 60 days. Content that ranks well at first but starts bleeding traffic after two weeks? That's usually a thin-expertise problem. It slipped through gates 1 through 3 just fine but couldn't survive the reader test.
Proofreading catches typos. A 4-gate framework catches something far worse: hallucinated statistics, missing expertise signals, and ethical gaps that destroy both your rankings and credibility.
On the ethics side, governance documentation isn't optional busywork. Your team needs written policies covering three areas: AI disclosure (when and how you tell readers AI helped create the content), copyright handling (who owns AI-generated drafts, what training data restrictions apply), and role boundaries (AI replaces roughly 27% of content tasks, not the humans doing them). Skip this documentation, and you're one algorithm update away from a compliance crisis.
For a deeper look at building these gates into a full AI writing workflow, know this: the production sequence matters just as much as the gates themselves. Bolting quality checks onto an existing process? That gets you marginal improvements at best. But teams that restructure their entire workflow around these four gates see compounding gains in organic traffic and real content longevity.
Teams running fewer than three structured checkpoints consistently fall behind on accuracy and search visibility. Four gates isn't bureaucracy. It's the minimum viable system for publishing AI content that actually holds up under scrutiny.
Frequently Asked Questions About AI Content Best Practices
Does Google penalize AI-generated content in 2026?

No. Google penalizes unhelpful content, regardless of who or what created it. Their ranking systems assess usefulness, accuracy, and E-E-A-T signals. Disclosing AI involvement won't hurt you if your content genuinely answers the query with clear, verifiable expertise.
What are the best practices for improving AI content visibility in search?
Structure every article so both traditional search engines and LLMs can pull clean answers from it. Frame your H2s and H3s as questions, then open each section with a definition-style sentence. Cap paragraphs at four sentences. Add FAQ schema markup to send search engines explicit Q&A signals. Accuracy isn't optional here: named sources, specific numbers, and cited research make your content far more citable across AI Overviews and featured snippets.
How do you maintain brand voice when using AI content tools?
Define your voice before you hit generate. Not after. Feed your style guide, tone examples, and audience personas directly into the prompt. Sure, editing afterward catches mistakes. But it won't inject personality into flat prose that never had any to begin with.
What is the difference between GEO and AEO?
GEO targets citations within LLM-powered tools like Google AI Overviews and ChatGPT's browsing mode. AEO, on the other hand, zeroes in on featured snippets and direct answer boxes in traditional SERPs. Both demand structured, factual content. So what's the real difference? GEO puts a premium on source attribution and quotable statements. AEO rewards concise, schema-marked answers built to slot right into a snippet box.
How often should AI-generated content be reviewed for accuracy?
Every piece, every single time. Run a 4-gate review: confirm the brief before generation, scan the draft with automated fact-checking tools, have a subject-matter expert sign off before it goes live, then audit published content quarterly to catch outdated claims or broken citations.
Start Producing AI Content That Actually Ranks
The change isn't about writing faster. It's about publishing smarter content, organized for GEO, rooted in E-E-A-T, and built within a quality framework that catches problems before they chip away at your organic traffic. Explore the automation playbook to see how these best practices connect into a repeatable, scalable system you can actually run consistently.
Ready to stop treating AI content as a drafting crutch and start building a real publishing pipeline? Get started with Wyrote.
Related Articles



Ready to automate your SEO content?
Wyrote creates publish-ready articles from your keyword strategy.
Get Started Free