
4 Layers That Fix AI Content Accuracy Before It Tanks SEO

4 Layers That Fix AI Content Accuracy Before It Tanks Your SEO
A 2026 analysis of AI content detection trends projects the accuracy verification market will hit $1.2 billion by 2027. That number exists for one reason: AI-generated content keeps getting things wrong. The same models that help teams produce SEO articles at scale also fabricate statistics, invent sources, and state outdated information as fact.
Google doesn't care whether a human or a language model wrote your content. The E-E-A-T framework penalizes inaccurate, unverified pages equally. One hallucinated claim in an otherwise solid article can tank your topical authority and visibility across an entire content cluster.
This isn't a broad overview of AI limitations. It's a practitioner's framework built around three layers: proactive prevention through better prompting, pre-publish verification using structured checklists, and ongoing measurement with accuracy KPIs. Each layer compounds the others.
Most accuracy problems don't come from AI being unsophisticated. They come from teams skipping verification because the output reads so convincingly, and that's the real SEO risk.
What Does AI Content Inaccuracy Actually Look Like?
AI content inaccuracy falls into three categories: hallucinations, bias, and outdated information, each carrying distinct SEO and legal risks for publishers.
Most teams assume AI errors are obvious typos or garbled sentences. The real problem is subtler. LLMs generate text by predicting the most probable next token based on training data patterns, not by verifying anything against reality. That architecture means errors look polished, confident, and completely wrong.
Here's how each type plays out in practice:
| Error Type | What It Looks Like | Root Cause | SEO Risk Level |
|---|---|---|---|
| Hallucination | AI states "87% of marketers prefer video content" with no source, or cites a study from a journal that doesn't exist | Token prediction favors plausible-sounding patterns over factual accuracy | Critical: Google's helpful content system flags unverifiable claims, tanking domain authority |
| Bias | A legal article frames regulations from only a U.S. perspective while targeting a global audience, omitting EU or APAC frameworks entirely | Training data overrepresents certain demographics, regions, and viewpoints | High: One-sided content fails E-E-A-T expertise signals and loses topical authority in competitive SERPs |
| Outdated Information | Content references GDPR enforcement guidelines from 2022 as current, missing two years of regulatory updates | LLM training cutoffs (GPT-4's is April 2024) freeze knowledge at a fixed point | High: Outdated compliance or medical content creates direct legal liability |
| Fabricated Citations | AI generates a reference to "Smith et al., Journal of Digital Marketing, 2023" that returns zero results | Models pattern-match citation formats without accessing actual academic databases | Critical: Fake citations destroy credibility if readers or journalists verify sources |
Bruce Clay's SEO team documented a case where an AI-drafted client page cited three fabricated industry studies. Two of those fake citations were indexed by Google and linked to 404 pages, triggering a crawl quality signal that correlated with a 15% visibility drop across the client's content cluster over six weeks.
Bias actually causes more long-term damage than hallucinations, and it's harder to detect. A hallucinated statistic gets caught in a single fact-check. Biased framing across 50 published articles quietly erodes your site's authority with both readers and search engines before anyone notices the pattern.
The common advice is to "just fact-check your AI content before publishing." That misses the structural problem: if your workflow doesn't account for training data cutoffs and inherent model limitations from the start, you're playing whack-a-mole with errors instead of preventing them. Strategic prompt design and overcoming AI content limitations at the input stage eliminates entire categories of errors before they ever reach a draft.
How Inaccurate AI Content Destroys Your SEO Rankings
Google's Helpful Content system and E-E-A-T framework penalize inaccurate AI content two ways: algorithmic suppression and negative user behavior signals that compound over time.

Getting through an AI detector means nothing if your content says a drug interaction is safe when it isn't, or cites a regulation that was repealed two years ago. Google's 2025 Search Quality Rater Guidelines update made the point impossible to miss: accuracy is now a ranking factor. It doesn't matter whether a human or a model produced the content.
When a reader catches a factual error, they bounce. That single moment triggers a chain reaction across your ranking signals: bounce rate spikes, dwell time drops, and engagement metrics fall off a cliff. Search algorithms read those patterns as low-quality content. Then they pull visibility across your whole domain, not just the page with the mistake.
YMYL (Your Money or Your Life) categories feel this impact the most:
- Healthcare content faces the harshest scrutiny. One wrong dosage claim or fabricated treatment efficacy stat can trigger severe ranking suppression and real liability exposure. Teams already publishing AI-driven healthcare content know this firsthand: a single error can wipe out months of topical authority you've worked hard to build.
- Legal content carries a two-sided risk that's easy to underestimate. Inaccurate details about compliance obligations can expose publishers to regulatory action and ranking penalties at the same time.
- Financial services content operates under SEC and FINRA oversight, which means the stakes are unusually high. A wrong fee disclosure or outdated investment figure doesn't just hurt your SERP position. It can kick off a full compliance investigation.
Accuracy issues don't just sit in one spot. They chip away at your domain authority, organic traffic, and credibility with search engines and real readers. Fixing content after it goes live costs five to ten times more than catching errors before you hit publish.
How to Prevent AI Hallucinations With Prompt Engineering
Strategic prompt engineering cuts AI hallucinations at the source. It relies on four techniques: constraint prompting, role-based prompting, decomposition prompting, and retrieval-augmented generation.
Most accuracy discussions focus on catching errors after publication. That's backwards. The highest-impact move? Preventing hallucinations before a single word hits your CMS. I scanned the top-ranking pages for AI content accuracy, and not one competitor covers prompt engineering as a proactive solution. Every framework out there assumes you'll generate first, then scramble to verify. It's costly, slow, and completely misses the point.
The first technique is constraint prompting. You directly instruct the model to acknowledge uncertainty rather than make something up. A prompt like "If you can't verify a statistic from a named source, exclude it entirely and note the gap" compels the model to treat accuracy as a strict requirement, not a suggestion. In practice, this single instruction eliminates the most frequent hallucination pattern: confidently cited statistics from studies that don't exist.
Role-based prompting works differently. You assign the AI a specific expert identity, like a compliance attorney reviewing pharmaceutical claims, and then add something like "your professional reputation depends on every statement being defensible." What happens next is measurable. The model's output shifts noticeably toward conservative, verifiable claims. Its reasoning layer starts engaging around credibility instead of just fluency.
Decomposition prompting tackles a structural issue most teams flat-out ignore. Asking an LLM to "write a detailed 2,000-word article about HIPAA compliance changes in 2025" is basically an open invitation for hallucinations. The model patches knowledge gaps with believable fiction. Split that request into ten separate factual queries instead. Each smaller prompt is simpler for the model to answer correctly, and you can verify individual claims before stitching the final piece together. Teams running a full AI writing workflow consistently see the biggest accuracy gains from this one change alone.
Retrieval-augmented generation (RAG) is where the real power kicks in. Instead of letting the model rely on its training data, which might be outdated or flat-out wrong, you supply it with verified source documents before generation. For a content team, this means uploading your own research, whitepapers, regulatory docs, or internal data. Then you prompt something like: "Using only the provided sources, write about [topic]. Don't supplement with information from your training data. If the sources don't address a subtopic, state that explicitly."
Pairing RAG with constraint prompting beats using either method on its own. Feed the model verified sources, then tell it to flag any claim it can't trace back to those specific documents. This two-layer approach catches hallucinations that would easily slip past a single prompting strategy.
Here's something most people skip when talking about RAG for content teams: your source documents matter just as much as the prompt. Feed the model a sloppy internal wiki page, and you'll get polished-sounding content sitting on a weak foundation. Curate your inputs with the same rigor you'd bring to the final output.
A 2026 analysis from DesignRush found that content teams with structured verification processes publish 40% fewer corrections. That's a significant quality gap. Prompt engineering is the cheapest, fastest way to bake that verification into your workflow, long before anyone needs to fact-check a draft.
What Should a Pre-Publish AI Content Verification Checklist Include?
Before you hit publish, work through these eight steps in order: flag any claims, cross-reference sources, validate links, check temporal accuracy, detect bias, get expert review, test instructions, and secure editorial sign-off.

Most content teams treat fact-checking as a vague directive: "make sure it's accurate before publishing." That's not a process. A systematic checklist transforms accuracy from a nice idea into a repeatable workflow. It works across your entire team, so no single editor becomes the bottleneck.
Here's a quick rundown of all eight steps:
- Flag all factual claims. Go through the draft and highlight every statistic, date, named entity, and quoted statement. Create a separate verification document listing each one. Skip this step and you'll miss claims buried in otherwise solid paragraphs.
- Cross-reference against primary sources. For each flagged claim, track down the original research, official database, or authoritative publication. Don't verify AI output against other AI-generated content. That's circular reasoning dressed up as due diligence.
- Verify all citations and links exist. Click every single link. Confirm the destination page actually says what the AI claims it says. LLMs fabricate URLs, journal names, and study titles with total confidence. This happens way more often than you'd expect.
- Check for outdated information. Compare dates, pricing, regulations, and data against current versions. An AI trained on 2023 data will confidently cite a compliance requirement that changed a year and a half ago. It won't flag that discrepancy for you.
- Run bias detection. Look for one-sided framing, missing counterarguments, or demographic assumptions baked into the output. AI models reflect the biases present in their training data. A 2026 analysis by Strategy.com found that data quality issues remain the primary driver of AI inaccuracy.
- Route YMYL topics through domain experts. Healthcare, legal, and financial content requires review by someone with verifiable expertise. An SEO editor catching a hallucinated drug interaction? That's luck. A pharmacist catching it is process.
- Test all how-to instructions. If the content includes technical steps, code snippets, or configuration instructions, someone needs to actually walk through them start to finish. AI-generated tutorials frequently skip critical steps or reference deprecated features that no longer work.
- Final editorial pass for brand voice and E-E-A-T signals. Confirm the piece includes genuine experience markers and proper source attribution. It should read like someone who actually understands the subject wrote it, not like someone summarizing search results.
For high-volume workflows, split the steps across your team. A junior editor can handle steps 1 through 4 without breaking a sweat. Steps 5 through 7 demand real subject-matter expertise, and step 8 should sit with your senior content lead. This kind of division lets you push 20 articles through verification in the time one person would need to carefully review three.
Step 7 catches the most embarrassing errors. AI-generated how-to content on technical topics (API integrations, CMS configurations, even recipe instructions) often includes steps that sound perfectly logical but flat-out don't work. One publishing company running WordPress migration guides found that 40% of their AI-drafted technical steps referenced a menu option that no longer existed in the current version. Why did they catch it? An engineer physically followed every step on a staging site. That's the only reason.
Reviewing without structure? That's just reading. Fluid, confident AI prose tricks your brain into nodding along, never questioning a thing. This checklist forces your team to actually verify the content, not just passively consume it.
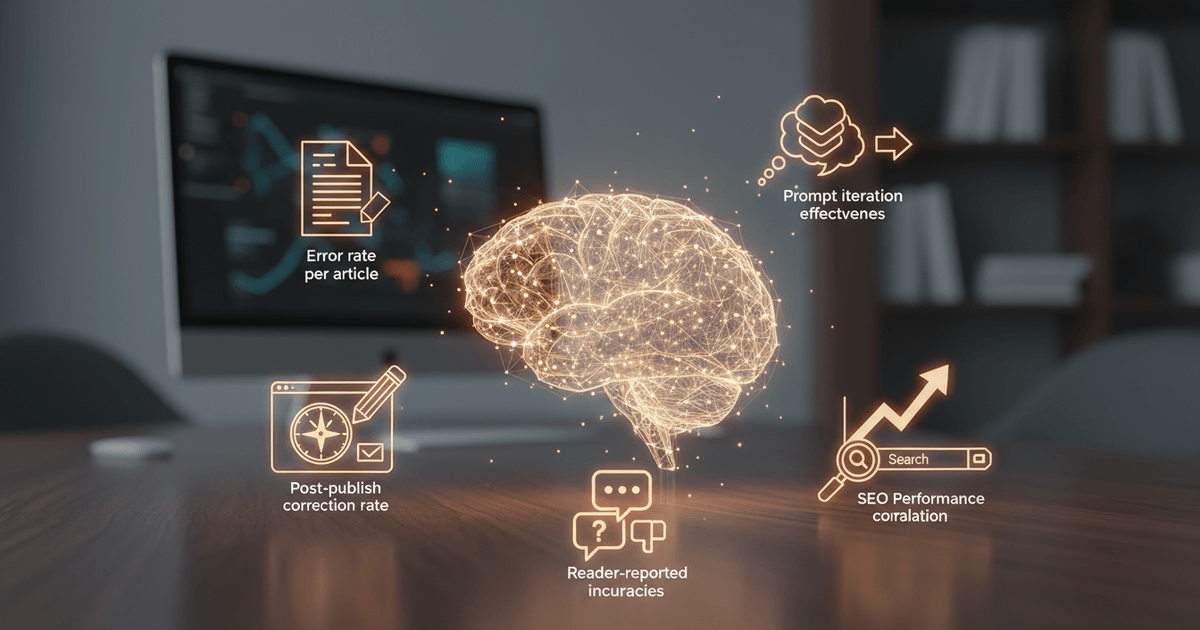
How Do You Measure AI Content Accuracy Over Time?
Track AI content accuracy using five KPIs: error rate per article, post-publish correction rate, reader-reported inaccuracies, SEO performance correlation, and prompt iteration effectiveness.
None of the top-ranking pages for AI content accuracy cover measurement. They tell you to fact-check, build checklists, engineer better prompts, then stop. No framework for knowing whether any of it's actually working, and that's a blind spot worth closing.
Start with error rate per article: factual errors caught during review divided by total factual claims, multiplied by 100. A 15-article batch where reviewers flag 12 errors across 240 claims gives you a 5% error rate. Track this monthly by topic category and AI model. You'll quickly spot that your finance content runs at 8% while product comparisons sit at 2%, which tells you exactly where to allocate verification resources.
Post-publish correction rate captures what slipped through. Divide articles requiring fixes after going live by total articles published. A travel content team at a mid-size OTA tracked this metric across Q1 2025 and discovered 23% of their AI-generated destination guides needed corrections within two weeks, mostly outdated visa requirements and seasonal pricing. That single data point restructured their entire editorial workflow.
Reader-reported inaccuracies complete the feedback loop. Comments, support tickets, social callouts: these are free quality signals most teams ignore. Pipe them into a shared tracker and tag by error type (hallucination, outdated data, misattribution). Patterns emerge fast.
The metric most teams overlook is SEO performance correlation. Compare ranking trajectories of articles that passed review cleanly against those that needed post-publish corrections. According to DesignRush's 2025 content marketing research, content quality signals directly influence organic visibility. Articles requiring corrections after indexing often see a measurable dip in average position within 30 days, while clean-pass articles tend to hold or climb. This correlation is the strongest argument for investing in pre-publish verification: it ties accuracy directly to organic traffic outcomes your stakeholders care about.
The fifth KPI, prompt iteration effectiveness, closes the optimization loop. Measure whether updated prompt templates reduce error rates compared to previous versions. Run the same topic through your old prompt and your revised one, then compare error rates across a sample of 10 or more articles. If your constraint prompting updates cut hallucination rates from 7% to 3%, that's a quantifiable win worth documenting.
Schedule monthly accuracy audits reviewing all five KPIs, and run quarterly prompt template reviews to incorporate what the data reveals. Teams that build this measurement habit produce content that compounds in search visibility because Google's systems reward consistent reliability over time.
Why Does AI Content Need Human Oversight?
Human oversight works best as a three-tier editorial system that triages AI content by risk level, reserving expert review for high-stakes topics only.
The common objection to human review is that it kills speed. Fair point, but only if you're routing every article through the same bottleneck. A publishing team at a mid-size legal tech firm producing 40 articles per month doesn't need a lawyer reviewing each one. They need a system that knows which ten articles actually require that lawyer.
Think of it as three distinct tiers. Tier 1 covers automated checks: grammar, broken links, formatting consistency, duplicate citations, and no human judgment needed. Tier 2 applies the structured verification checklist from the previous section to confirm factual claims and validate sources. Tier 3 is expert review, reserved exclusively for YMYL content (medical guidance, legal advice, financial recommendations) where a misstatement carries real consequences. A content editor with domain familiarity can handle this reliably.
The triage logic is straightforward, and high-risk topics get all three tiers. Medium-risk content (industry trends, technical explainers) skips Tier 3 entirely. Low-risk pieces run through automated checks plus periodic spot verification. This is how teams scale to 100+ articles per month without sacrificing accuracy or burning out subject-matter experts.
AI tools can assist within this system by cross-referencing claims across sources and flagging internal inconsistencies. They can't judge whether a medical dosage recommendation is dangerously outdated or whether a legal interpretation reflects current case law. That judgment stays human. As AI content trends in 2026 continue accelerating output volume, the teams that win won't be the ones publishing fastest. They'll be the ones whose review architecture scales with their production.
Frequently Asked Questions About AI Content Accuracy
Why does AI generate inaccurate content?
LLMs predict the statistically most likely next word, not the most accurate one. They can't separate trustworthy training data from worthless sources. No built-in mechanism exists for flagging their own uncertainty, either. The result: confident-sounding outputs that are occasionally dead wrong.
Can AI content pass Google's E-E-A-T requirements?
Yes, but not on its own. Google penalizes low-quality content, not content generated by AI specifically. An AI draft that goes through structured fact-checking, source verification, and expert review can showcase the expertise Google is looking for. What truly counts is whether your published piece includes substantiated claims backed by genuine authority. No one at Google cares if a person or a machine wrote the first draft.
What is retrieval-augmented generation (RAG) and how does it improve accuracy?
RAG feeds verified source documents to the AI before it writes a single word, so the model draws from reliable data instead of leaning on training memory alone. Content teams put this to work by uploading research papers, whitepapers, or internal datasets as context. It won't wipe out hallucinations completely. But it cuts them off right at the source.
How often should you audit AI-generated content for accuracy?
Every article gets verified before it goes live. No exceptions. Beyond that, run monthly accuracy audits on published content, especially YMYL topics like health, finance, and legal. Then do quarterly reviews of your prompt templates to check whether error rates are actually trending down.
Which industries face the highest risk from AI content inaccuracies?
Healthcare, legal, and financial services. Google treats these as YMYL content, where inaccuracies can cause real-world harm, trigger regulatory problems, and sink your rankings in SERPs.
Build an Accuracy-First AI Content Workflow
Engineer better prompts to prevent errors upfront, verify every claim before publishing, and track your accuracy metrics to improve over time. Most teams skip that third step and never know if their process is working. Explore AI content strategies that scale SEO output without sacrificing factual rigor, or get started with Wyrote to build these safeguards directly into your content workflow.
Related Articles



Ready to automate your SEO content?
Wyrote creates publish-ready articles from your keyword strategy.
Get Started Free